
外观
把个人 LifeOS 做成一个可运行系统:LifeOS Center 第一版复盘
我最近把一个很私人、也很工程化的项目推进到了第一版可用状态:LifeOS Center。
它表面上是一个 Web 管理台,背后其实是在解决一个更朴素的问题:一个人的生活、财务、健康、资料、技术运维和自动化入口,能不能不要散落在聊天记录、表格、备忘录和一堆临时脚本里。
所以这篇文章不是产品发布稿,而是一次技术复盘。我会从项目定位、模块设计、技术架构、OpenClaw 自动化接入、NAS 部署和验收闭环几个角度,把这套系统完整讲一遍。

它到底是什么
LifeOS Center 是一个个人 LifeOS 的统一执行前台。第一版的目标很克制:能登录、能点、能录、能看、能导出,并且能通过 Docker Compose 在 NAS 上独立运行。
这里的“克制”很重要。很多个人系统项目容易一开始就奔着全自动、全智能、全平台同步去做,结果很快变成不可维护的胶水工程。我这次先把核心问题压到几个明确边界里:
- 人能在网页里稳定维护记录。
- 自动化代理能把结构化消息交进来。
- 高风险能力要有确认、幂等、审计和脱敏。
- NAS 上要能部署、备份、恢复演练和复验。
- 文档、体检脚本和页面展示要尽量同源,不靠记忆维护。
第一版覆盖的主模块包括总览、中枢、健康、财务、枢纽、档案、文化和设置。它不是一个“更漂亮的备忘录”,更接近一个个人系统的控制台。
模块不是菜单,而是边界
这套系统里,模块划分不是为了导航好看,而是为了让数据和职责不要互相污染。
总览负责把当天最需要看的状态聚合出来:提醒、财务状态、健康趋势、模块状态和 AI 科学分析。它不直接承担复杂写入,只做轻量聚合和入口。
中枢负责执行层:今日记录、每周检查、备忘、日程、重大决策、战略文档和白板。它更像“今天我到底在推进什么”的地方。
健康模块负责事实、提醒和复核:家庭成员、健康记录、身体指标、用药提醒、家用药品、体检指标和待复核事项。它有一条硬边界:系统只记录事实,不自动生成医疗诊断。
财务模块是风险最高的业务区之一,所以它不完全复用通用记录逻辑。流水、预算、债务、账户、投资、大额审批、月度摘要和图表都有更严格的领域规则,财务入口也有二次解锁。
枢纽模块负责技术和数据安全:软件服务、硬件资产、备份清单、备份检查、维护记录、工具、工作流、灾难恢复手册和技术采购。它回答的问题是:系统能不能稳定运行,数据能不能找回,技术采购值不值得提交。
档案模块负责可沉淀材料:资料、成果、简历素材、作品集素材和信息资源。这里的重点不是“存文件”,而是让素材有上下文、有状态、有未来用途。
设置模块是全局运行收口:系统状态、接口配置、安全检查、访问防护、外部状态、API 清单、媒体库、导出、系统手册、日志和更新记录。设置只展示全局状态和跨模块能力,不复制业务明细。
这几个模块合在一起,形成的是一个“个人运行系统”的最小闭环:记录事实、安排行动、追踪风险、沉淀材料、检查运行状态。
技术架构:让普通记录简单,让高风险能力专用
技术栈本身不复杂:
- Next.js + TypeScript
- Prisma + PostgreSQL
- Docker Compose
- 单管理员账号,HttpOnly Session Cookie
- NAS 上独立运行,公网入口优先通过反向代理暴露
复杂点在于怎么让这么多模块不变成重复代码。
LifeOS Center 的大部分普通记录页由“模块配置 + 通用记录面板”驱动。实体字段、表单、列表、筛选、分页、保存、编辑和删除都尽量走统一路径。这样新增一个普通记录实体时,不需要从零写一套页面。
但系统没有把所有东西都塞进通用 CRUD。财务、媒体上传、系统设置、访问防护、外部状态、OpenClaw intake、备份状态等能力,都走专用 API 和专用 lib。原因很简单:通用能力负责省力,专用能力负责兜住风险。
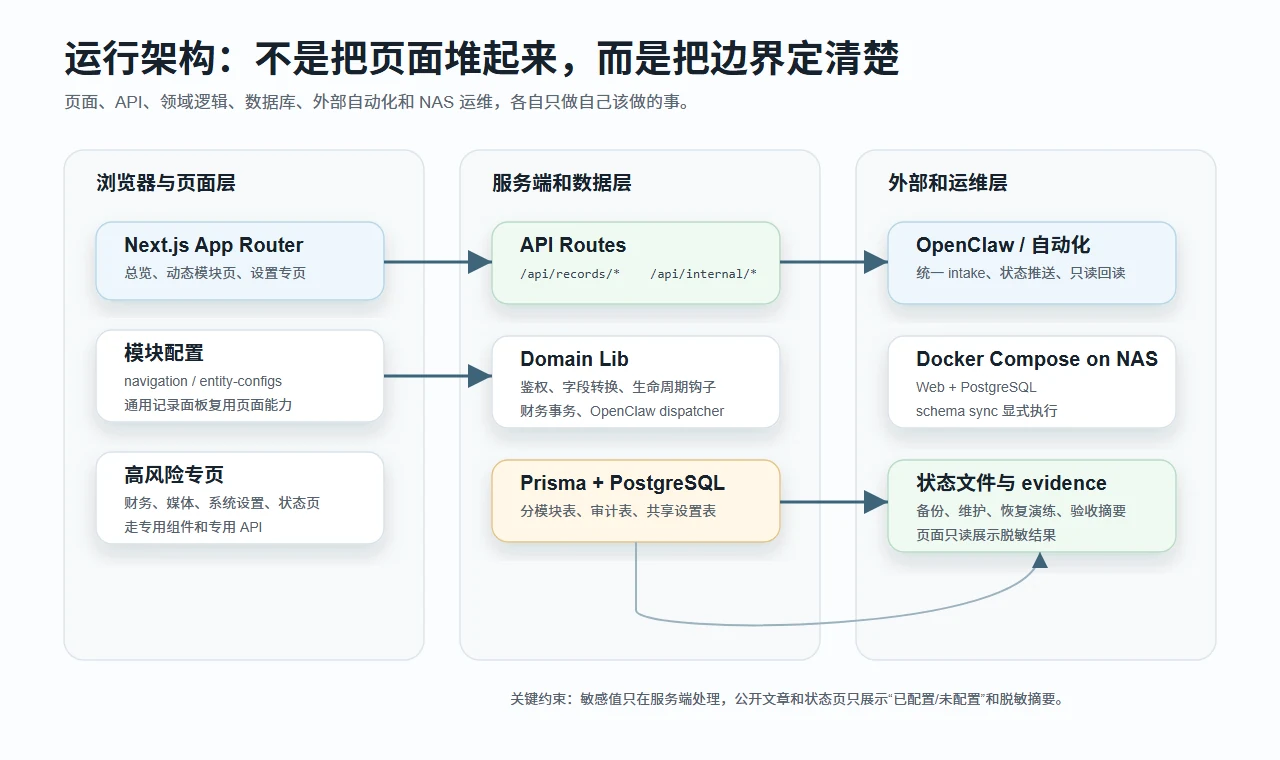
一个简化后的调用路径大概是这样:
浏览器页面
-> Next.js API Route
-> 领域 lib / 通用 records 编排
-> Prisma
-> PostgreSQL
OpenClaw / 外部自动化
-> 内部 intake API
-> intent 校验、幂等、确认、审计
-> 模块 dispatcher
-> 对应业务表
NAS 运维脚本
-> 状态 JSON / evidence 包
-> 设置页只读展示
-> 本地复核脚本检查我很喜欢这个结构的一点是:每层都知道自己不该做什么。页面不直接碰密钥,设置页不复制业务数据,自动化入口不绕过确认,状态页不展示完整日志,公开文档不写敏感路径。
OpenClaw 接入:聊天输入不是直接落库
LifeOS Center 和 OpenClaw 的关系,可以理解成“一个负责理解输入,一个负责安全落库”。
OpenClaw 可能来自微信、语音、OCR 或其他输入通道。它把用户表达整理成一个结构化 envelope,再交给 LifeOS。LifeOS 不盲信这个请求,而是重新做鉴权、schema 校验、intent 校验、幂等去重、确认边界、审计脱敏和领域写入。
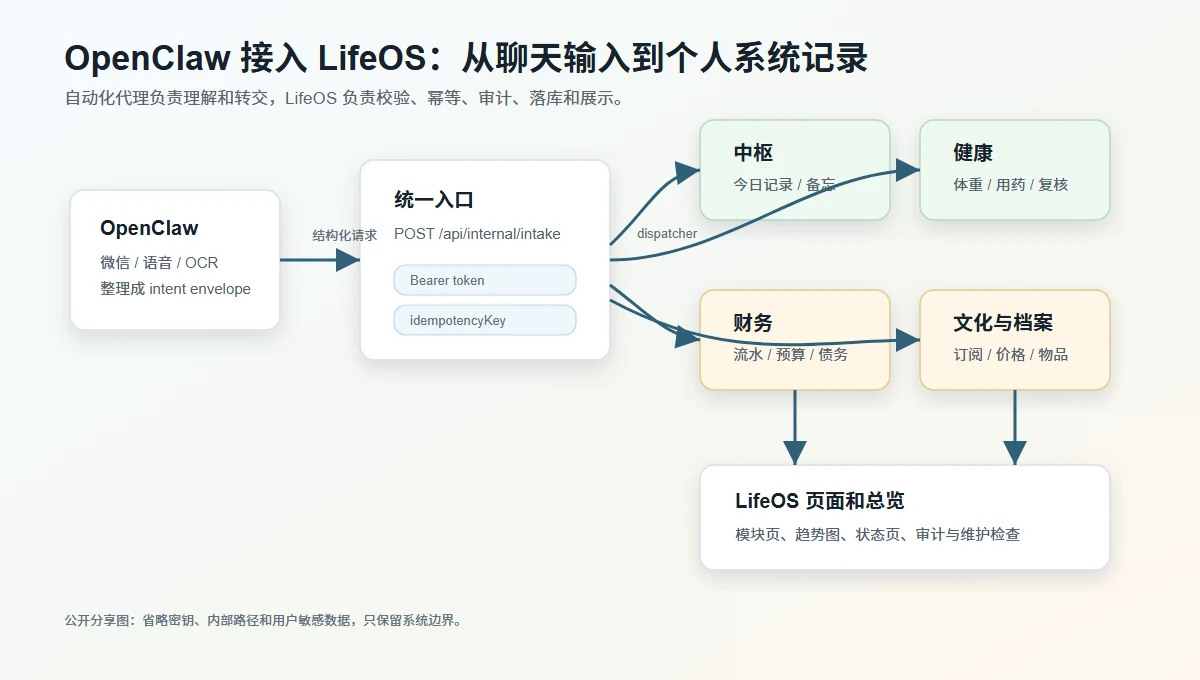
统一入口采用类似这样的 envelope 思路:

这里最关键的不是 JSON 字段长什么样,而是它把几个问题拆开了:
intent表示这次到底想做什么。source和idempotencyKey决定请求能不能被去重。needsConfirmation和confirmed表示高风险写入有没有经过确认。rawText保留用户原始表达,但入库前要脱敏。payload才是具体业务字段。
第一版已经接入了财务、健康、中枢、文化生活台账和决策相关的一批 intent。比如新增财务流水、设置预算、记录还款、写入健康记录、保存身体指标、创建日程、写今日记录、查询常备药、更新订阅状态等。
但有些能力明确不支持:删除类操作、财务密码修改、清空日志、长期人格记忆、医疗诊断、处方建议、药品可用性判断。这不是没做完,而是第一版故意不开放。自动化系统最怕的不是不会做,而是“好像会做”。
一个具体坑:身体指标为什么要结构化
这次第一版收尾里,有一个很典型的小坑:小龙虾发送今日记录时,身体数据很多没有显示出来。
原因不是页面坏了,而是数据语义没有落到正确位置。体重、BMI、体脂率、内脏脂肪、骨骼肌、基础代谢、水分、骨量、蛋白质、身体年龄、心率、腰围这些数据,本质上不是一条普通健康备注,而是一组可趋势化的身体指标。
所以最后的设计是:体检原始记录可以保留,但身体组成类数据要镜像到底层健康指标记录,再由 /health/body-metrics 结构化展示。
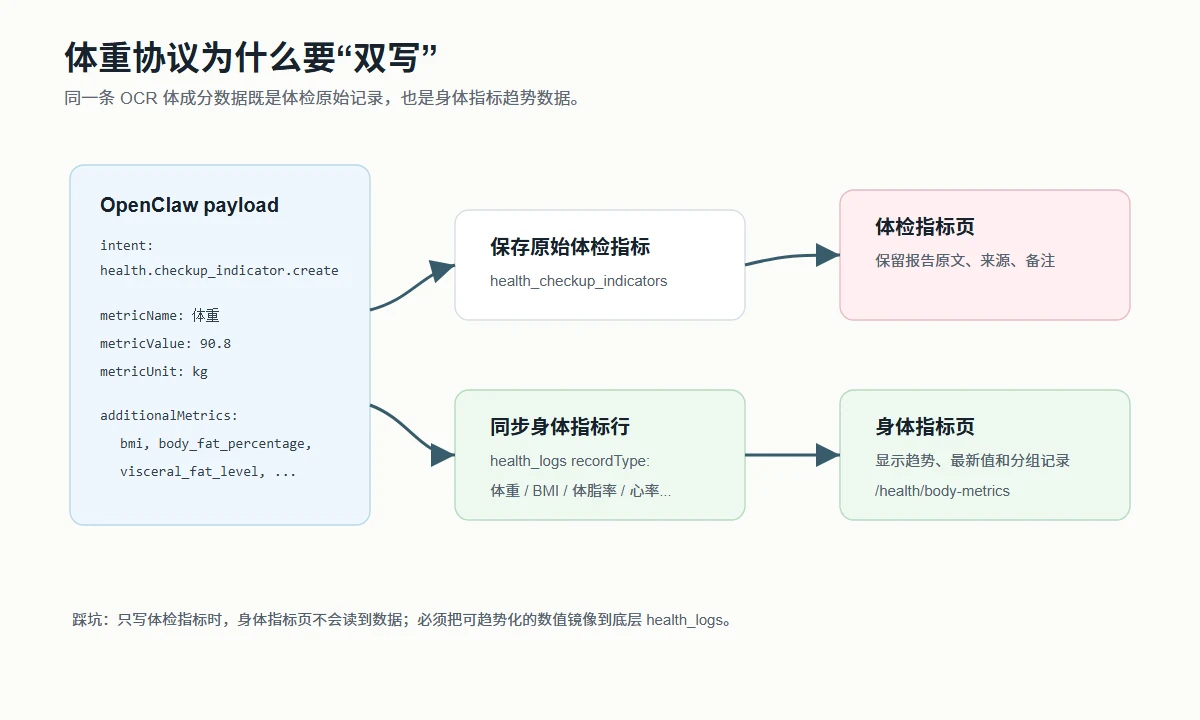
这个案例给我的提醒是:自动化入口不能只看“有没有写进数据库”,还要看“写进了哪个语义位置”。否则它会出现一种很迷惑的状态:接口返回成功,数据也存在,但用户在真正需要的页面看不到。
系统状态页:维护者视角要翻译成用户视角
第一版里还有一个很现实的 UI 问题:系统状态页一开始偏维护者视角,路径、接口名、生成时间、接收时间、告警接口这些信息铺得太满。
但用户真正需要看的不是“这个检查背后读了哪个文件”,而是:
- 现在是不是正常?
- 哪一块需要我处理?
- 最近一次更新时间是否新鲜?
- 如果异常,我下一步该去哪?
所以状态展示后来收敛成更窄、更中文、更像状态灯的形式。路径只在有必要排障时出现,普通状态显示为 OK、警告或失败;时间也不拆成让人难受的多行字段。
这件事看起来是 UI 细节,其实是系统设计原则:状态页不是日志查看器。状态页要帮人更快做判断,而不是把实现细节原样倒出来。
NAS 部署:能跑不等于能交接
LifeOS Center 的运行目标不是“我本地启动过”,而是能在 NAS 上长期运行。
部署层主要由 Docker Compose 承载:Web 容器、PostgreSQL、运行时数据目录、备份目录和状态文件目录分开。数据库结构同步不放在普通容器启动里偷偷执行,而是走显式 schema-sync profile。这样做麻烦一点,但能避免生产启动时不知不觉改库。
更重要的是,系统不是靠一句“部署成功”交接,而是靠 evidence:
- 本地静态体检结果
- 构建结果
- NAS runtime 摘要
- 备份和恢复演练状态
- 每周维护状态
- 浏览器 smoke 结果
- OpenClaw/API 验收记录
- 文档索引和更新日志
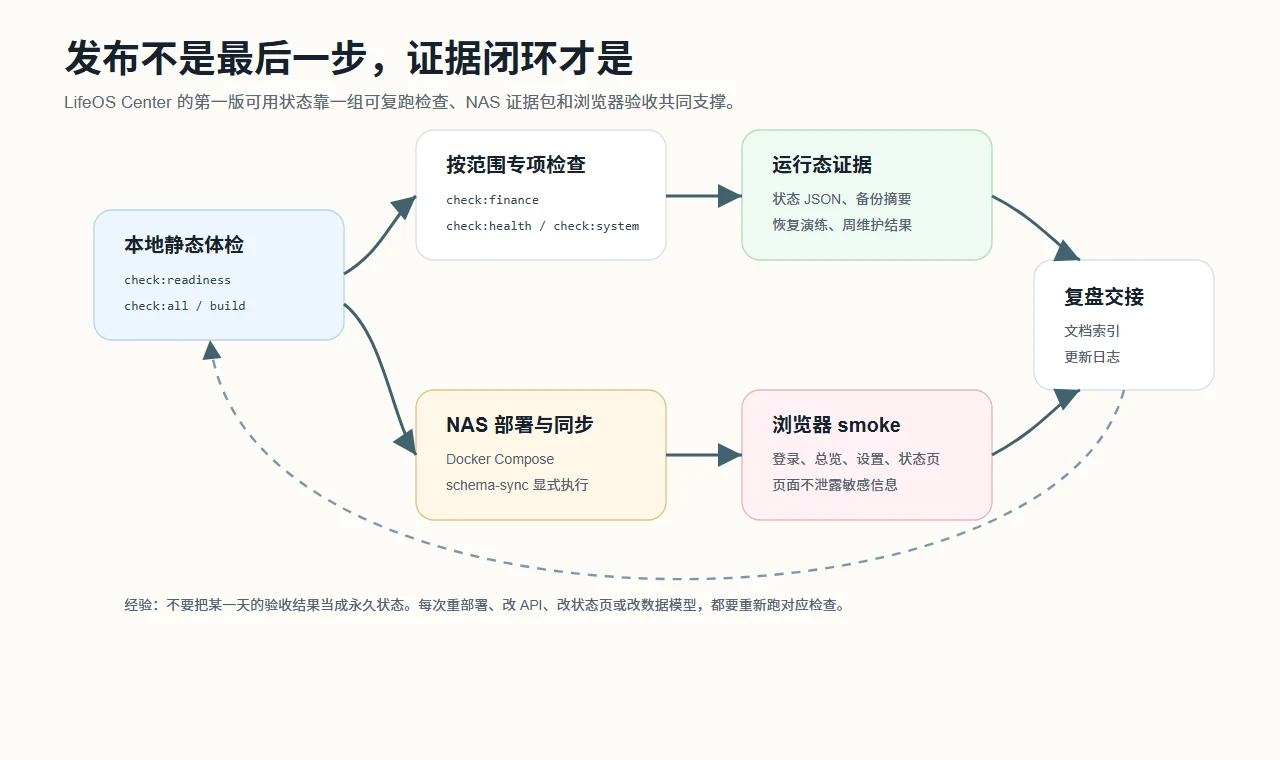
第一版交接里记录过一次 check:readiness 结果为 90 pass, 0 warn, 0 fail。但我不把它当成永久结论。只要重部署、改 API、改状态页、改数据模型、改外部接入,就应该重新跑对应验证。
这个项目里常见的检查入口包括:
npm run check:readiness
npm run check:system
npm run check:security
npm run check:all
npm run build涉及具体模块时再追加:
npm run check:finance
npm run check:health
npm run check:tech
npm run check:ui
npm run check:openclaw-heartbeat部署后的浏览器 smoke、NAS evidence 复核和外部验收汇总,则用来确认真实环境没有被本地静态检查遗漏。
安全边界:少展示,比多展示更难
个人系统有一个天然风险:里面的数据都很真实。
所以 LifeOS Center 的安全策略不是只靠“不要泄露密码”这句口号,而是在多个层面做边界:
- 登录使用 HttpOnly Session Cookie。
- 财务模块有独立二次解锁。
- 敏感系统设置只展示已配置、未配置或脱敏摘要。
- 外部 Token 比对走服务端,不进入前端。
- 非媒体外呼有超时、响应体上限和错误脱敏。
- 媒体上传有文件数量、大小、MIME 和危险扩展名检查。
- 状态页不展示
.env、完整 Docker logs、数据库 dump、完整备份或 Authorization。 - 公开文章、截图和交接材料不写密钥、不写完整私有路径。
我对这类系统的一个判断是:少展示往往比多展示更难。因为“都打印出来”最省事,但它会把排障便利变成长期风险。真正可维护的状态页,应该把细节藏在受控排障流程里,把用户需要的判断留在页面上。
这次最有价值的几个工程经验
第一,先做可运行闭环,再追求智能化。
自动化入口很诱人,但如果网页、数据库、备份、恢复、验收都不稳,自动化只是把混乱放大。LifeOS Center 第一版先保证人可以登录、录入、查看、导出和复验,再让 OpenClaw 逐步接入。
第二,通用 CRUD 能省很多力,但不能覆盖一切。
普通记录适合配置化;财务、健康复核、媒体上传、系统设置、外部状态和自动化写入不适合假装普通。该专用就专用,反而能让系统更清楚。
第三,幂等是自动化入口的生命线。
语音、微信、脚本、网络重试都可能重复触发。同一个 source + intent + idempotencyKey 成功后只处理一次,可以避免重复流水、重复日程、重复健康记录。但复测修复时也要记得换新幂等键,否则会被旧成功结果挡住。
第四,状态页要服务使用者,不要炫耀实现。
路径、接口、状态文件、生成时间这些信息对维护者有用,但对日常用户是噪声。状态页应该优先表达“正常/警告/失败”“是否新鲜”“该去哪处理”。
第五,交接文档不是项目结束后的装饰。
这套项目在第一版发布时专门整理了主交接、文档索引、Windows 清理报告、验收说明、用户验证说明和更新日志。它们不是为了好看,而是为了让下一次维护不靠某个会话的上下文续命。
现在的状态
LifeOS Center 当前已经进入第一版可用状态:核心模块可用,NAS 部署路径和验收路径已经整理,OpenClaw 统一写入口已经覆盖一批真实 intent,系统状态页、API 清单、备份维护、健康结构化、财务弹窗和文档交接也完成了第一轮收口。
它还不是一个“完成”的系统。后面还会继续打磨 OpenClaw 的自然交互、更多模块的数据回读、状态页的信息层级、档案与枢纽的易用性,以及公开网站上的分享与说明。
但它已经越过了一个很关键的点:从一堆想法、记录和脚本,变成了一个能被部署、能被验证、能被交接、能继续生长的软件系统。
这大概就是我最想分享的部分:个人系统也可以按工程系统来做。不是为了把生活变成冷冰冰的表格,而是为了让那些重要的东西,有一个可靠的位置可以回来。